Bug #2335
closedSteady increasing clock drift in RTP from source BTS
100%
Description
While analyzing some of the packet captures, Pau encountered some serious issues with the clock of the source of the RTP stream drifting quickly towards high values such as 5000msecs of difference.
Wireshark was used on relatded protocol traces.
Select that one on the "RTP Streams" window and Press the button "Analyze". In there you can see a "Clock Drift: -5507 ms", and "Max Skew: -4040.34 ms" for a session which lasts 314 seconds.
In the list of packets on the same window, you can see the column "Skew" steady increasing over time (with minor instantaneous increases/decreases but with a steady increasing tendency). It seems if the call would have been longer, this drift would continue growing forever.
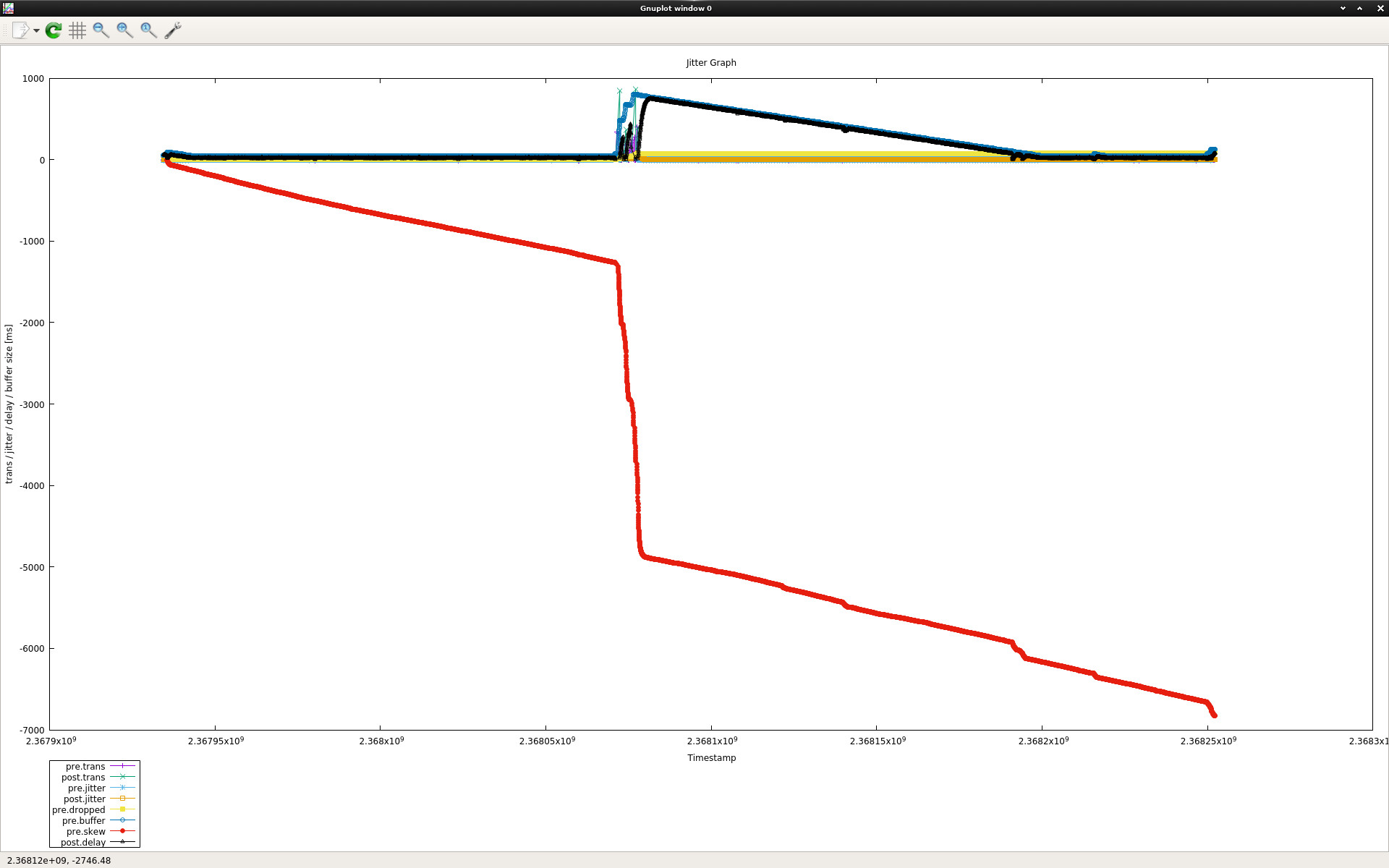
I also saw similar behaviour while running the pcap traces through the de-jitter implementation. At some point the de-jitter isreceiving packets arriving too late in time, and it starts dropping them. Then it increases the buffer size as it detects it as jitter, and it can continue a bit more until the issue happens again with the bigger buffer. It continues regulating itself until it reaches the maximum permitted buffer size configured. After that, it starts dropping all packets because all packets arrive too late. Looking at the graphs of how packets were delayed by the dejitter I had the impression the clock drift was appearing, so I added support to calculate an estimated drift from the source andit can take the drifting into account and can plot that too now. I attach a screenshot of the plot here for reference.
In the plot, you can see the red descending line which is the estimated skew from the source in milliseconds over time. It is calculated by smoothing the instantaneous delay of each packet towards the initial packet. In this plot as the de-jitter already takes into account the skew, packets are usually not dropped anymore. They are only dropped during the huge change of the skew in the middle of the plot because the smoothed value cannot represent correctly those enormous instantaneous checks, so it detects that as variability and the de-jitter increases the buffer size to account for that.
So even if the de-jitter can handle this better than before, it is still a main issue because the delay of several seconds is still there.
Files
Checklist
- determine osmo-bts version showing this
- check if current mastere also shows this
- ensure we always get PH-DATA.ind on each PHY for each codec frame, even if only junk was received (DTX, inteference, idle channel, ...)
- always return GSM_RTP_DURATION when creating RTP packet
- transform fn_ms_adj() to a pure checking function that raises alarms / prints logs whenever we're seeing missing codecx frames in l1sap_tch_ind()
Related issues
Updated by laforge almost 7 years ago
@Pau: Please indicate exactly with which OsmoBTS version this was observed, and try to reproduce this with current master.
Updated by laforge almost 7 years ago
- Checklist item determine osmo-bts version showing this added
- Checklist item check if current mastere also shows this added
- Checklist item ensure we always get PH-DATA.ind on each PHY for each codec frame, even if only junk was received (DTX, inteference, idle channel, ...) added
- Checklist item always return GSM_RTP_DURATION when creating RTP packet added
- Checklist item transform fn_ms_adj() to a pure checking function that raises alarms / prints logs whenever we're seeing missing codecx frames in l1sap_tch_ind() added
some remarks:
clock accuracy / pcap timestamps¶
The timestamps in the pcap files are all made with very inaccurate clocks of either the sysmoBTS ARM core or the x86 RTC of the bsc_nat. You cannot expect more than +/- 20ppm accuracy for regular crystals there. 20ppm means that 1/50000 of error can be expected. This means 1s of clock error is expected in 50000 seconds, i.e. 13.9 hours. So clearly, computer clock inaccuracy is not the cause of the phenomenon.
However, every 1000 seconds (16.66mins) you can expect the clock to drift about 20ms, i.e. one codec frame. So it is something that cannot be ignored. Furthermore, if you have two PCs with equally bad clocks at lowest (-20ppm) and the other at hights (+20ppm), then the error may accumulate to one codec frame within already 500s, i.e. after 8.3 minutes.
What does this mean:- we cannot trust timestamps of pcap files beyond the above-mentioned accuracy. The timestamp information is simply "wrong".
- we have to think about how each element of our chain will start to behave, once errors accumulate to that extent. If we e.g. receive RTP from a soft-switch that is sending too fast, we must have provisions to every so often drop a frame in our receiver (e.g. in OsmoBTS), rather than simply appending to queue. Otherwise, the queue would grow over time, and every quarter hour we'd have 20ms more delay in the audio.
GSM air interface and inherent jitter of 26-multiframe¶
GSM codec frames cover 20ms of real time, but are sent in 120ms/26=18.46ms over the radio interface. In every 26-multiframe, only 24 frames are used to transmit a GSM burst, leaving one frame for a SACCH burst, and one frame for neighbor measurements.
This means that the BTS will receive the PH-DATA.ind for TCH in irregular intervals from the PHY:- most of the time (3 out of 6 times) in 18.46ms spacing
- every so often in (2 outt of 6 times) in 23.08ms spacing
So there's an inherent jitter of about 4.62ms of the the codec frames coming up from the PHY. To that we have to add the combined jitter of the PHY data processing as well as the Linux scheduler jitter and the jitter created by different code paths inside OsmoBTS.
We are currently not doing any compensation of that jitter. Once we receive the codec frame from the PHY, we do whatever processing is reqired (re-formatting to RTP bit/byte order, measurement processing, ...) and send it off via the RTP socket. We're not using scheduled mode of ORTP.
how we generate the RTP timestamp + seq_nr in BTS transmit¶
RTP timestanps are generated by libortp based on 'duratin' values provied by the client program . libortp keeps state of the last timestamp and will then- add the 'duration' passed by the application to the last TS
- add 1 to the sequence number
and then send the packet off.
- a frame being corrupted on the radio interface. and its CRC failing as a result
- a frame being exposed to so much interference, that the link quality value goes below the BTS threshold
- the BTS somehow missing a PH-DATA.ind from the PHY
a frame being corrupted on the radio interface. and its CRC failing as a result¶
The behavior here is that we set the fBFILevel to a ridiculouse -200dB, so we make sure we always receive a PH-DATA.ind every time.
a frame being exposed to so much interference, that the link quality value goes below the BTS threshold¶
Here we have code in osmo-bts-sysmo/l1_if.c that checks for ·if (data_ind->measParam.fLinkQuality < btsb->min_qual_norm) and then returns early, without sending a RTP frame. This looks wrong to me. We should remove that early exit path and make sure for every PH-TCH.ind on a TCH we call into l1if_tch_rx which will then make sure to send a RTP frame. In the worst case, with a silent frame, or one explicitly marked as bad frame (depending on codec).
osmo-bts-trx has all kinds of other "early exit" paths in rx_tchf_fn() and rx_tchh_fn(), but they seem less critical as they only occur in cases of memory allocation failure or completely wrong RSL channel mode (with associated error messages).
the BTS somehow missing a PH-DATA.ind from the PHY¶
I think we simply should require form any PHY that this won't happen. Or rather, if it happens, we probably have much more serious trouble than voice delay/skew. Still, we should make sure that we raise immediately and alarm with the BSC and/or even consider to exit the process if we encounter such situations. This kind of failure shouldn't be hidden
DTX and our fn_ms_adj() function¶
src/common/l1sap.c:fn_ms_adj() is a function that tries to ensure the RTP timestamp is progressing as far as the actual sample clock has progressed. Normally, every 20ms we send a RTTP frame worth 160 samples. However, if for some reason we missed some frames (see above situations), then we try to compensate here by computing the number of 20ms voice frames expired since the last GSM frame number at which we received a PH-DATA.ind from the PHY.
The above logic is only active when uplink DTX is enabled.
I think we should- introduce test casese for the function, including corner cases where the FN wraps
- consider printing a WARNING message if we ever actually return something != 160 samples
- think about completely abandoing this. If we make sure that each supported PHY will always provide a PH-DATA.ind, even for a cmpletely empty channel (MS not transmitting during silence periods), then we will always send a RTP frame, no matter what.
Updated by pespin almost 7 years ago
- Checklist item check if current mastere also shows this set to Done
determine osmo-bts version: I requested the version running during the traces I got, we will hopefully receive them soon.
I was unable to reproduce the issue using current master. I also tried reproducing with reverting patch 5e87fdfcabc9cabe0025d7350b7ab31cdc4b6fa3 which was added a few months ago and seems related to the issue we are having, but even then I am unable to reproduce it.
Steps I am following to try to reproduce it:
- Run osmo-nitb in my PC with "-P" parameter.
- Attach 2 mobile phones to the sysmobts (running latest osmo-bts, or the one with the patch reverted).
- Start a call between both mobile phones and wait for 5-10 min while recording the call with tcpdump.
- Check with RTP analysis tool of wireshark
Updated by pespin almost 7 years ago
a frame being exposed to so much interference, that the link quality value goes below the BTS threshold¶
Here we have code in osmo-bts-sysmo/l1_if.c that checks for
·if (data_ind->measParam.fLinkQuality < btsb->min_qual_norm)and then returns early, without sending a RTP frame. This looks wrong to me. We should remove that early exit path and make sure for every PH-TCH.ind on a TCH we call intol1if_tch_rxwhich will then make sure to send a RTP frame. In the worst case, with a silent frame, or one explicitly marked as bad frame (depending on codec).
I have been checking the code around l1if_tch_rx() and handle_ph_data_ind() and I have at least one question: In l1if_tch_rx() we encode the data as AMR or any other codec, and the given codec to use comes from the first byte of data_ind->msgUnitParam.u8Buffer. However, I see some checks in there to assert that size of that buffer is at least 1. Which means: if l1if_tch_rx() is called with an empty buffer, we have no way of knowing which codec shall we use to send an empty audio frame to the upper level. I guess I need to use the correct one for that upper level link and I cannot use a random one right? Not sure how to solve that. Is the codec expected to change for a given link? Can we save the used codec in some of the structs storing context (struct gsm_lchan *lchan), then using that when the buffer is empty?
Updated by pespin almost 7 years ago
Another easier option would be to pass an empty rmsg msgb to add_l1sap_header() inside l1if_tch_rx(), then account for that (empty rtp payload) in l1sap_tch_ind(), only incrementing duration but sending nothing on this case, and on next RTP packet received from lower layer then clone it and send it twice, as if the older one was late. This way we don't need to care about RTP payload.
Updated by pespin almost 7 years ago
It seems this statemnt is actually not true in current code, at least for TCH channels:
a frame being corrupted on the radio interface. and its CRC failing as a result The behavior here is that we set the fBFILevel to a ridiculouse -200dB, so we make sure we always receive a PH-DATA.ind every time.
Which means if link signal with the MS is too low, a frame can be lost in a TCH channel ,and since we always return 160 samples from fnms_adj when no DTX is being used, that means we can have a clock drift.
I actually checked the behaviour with DTX enabled -> as the MS is not transmitting, frames are lost on the PHY layer (not received by osmocom stack) and fn_ms_adj detects the jump returning values bigger than 160 ms, from 320 to more than 2000. After I applied the following patch, then the clock is always synced correctly.
Updated by pespin almost 7 years ago
- Checklist item ensure we always get PH-DATA.ind on each PHY for each codec frame, even if only junk was received (DTX, inteference, idle channel, ...) set to Done
- Checklist item always return GSM_RTP_DURATION when creating RTP packet set to Done
- Checklist item transform fn_ms_adj() to a pure checking function that raises alarms / prints logs whenever we're seeing missing codecx frames in l1sap_tch_ind() set to Done
Updated by pespin almost 7 years ago
- Status changed from New to Feedback
Waiting for patches to be reviewed/merged.
Updated by laforge almost 7 years ago
you can see the related patches and their merge status at https://gerrit.osmocom.org/#/q/topic:rtp-fixes
Updated by laforge almost 7 years ago
To my knowledge, all related patches have now been merged to osmo-bts master
Updated by laforge almost 7 years ago
ping? I was hoping you would update the ticket after my last update...
Updated by pespin almost 7 years ago
- Status changed from Feedback to Resolved
Strange, I really had the impression I had answered you here, my bad.
Indeed all patches with related logic are merged, I therefore mark the issue as resolved.
There are still some related cosmetic patches waiting to be merged though: https://gerrit.osmocom.org/#/q/status:open+project:osmo-bts+branch:master+topic:cosmetic-fix
Updated by pespin over 6 years ago
- Related to Bug #2412: osmo-bts-litecell15 RTP clock drift added
Updated by ipse over 6 years ago
I've done a quick look at the patches and I see that they doesn't touch osmo-bts-trx. Does this mean that there is nothing to change there or that it's still using the old way of RTP handling?
Updated by pespin over 6 years ago
AFAIK osmo-bts-trx is also affected by these changes, as at some point its specific code calls l1sap_up to push packets up to the stack into l1sap_tch_ind() for TCH data. Over that region, there should be 2 changes in behaviour:
- It expects lower layer (osmo-bts-trx specific code) to no lose any TCH event. It will print an error "RTP clock out of sync with lower layer" instead of trying to account for that, to show up that this is not expected to happen and should be fixed in lower layers.
- In case empty data is received, it will update the RTP Clock accordingly.
Possible issues on osmo-bts-trx layer I can image:
- As explained by Harald in the original description, early exits: "osmo-bts-trx has all kinds of other "early exit" paths in rx_tchf_fn() and rx_tchh_fn(), but they seem less critical as they only occur in cases of memory allocation failure or completely wrong RSL channel mode (with associated error messages)."
- osmo-trx losing to trigger an event.
- UDP packet being lost between osmo-trx and osmo-bts-trx. --> should be possible to check for gaps and create dummy packets then push them up the stack.
Updated by ipse over 6 years ago
Thank you for the explanation!
pespin wrote:
AFAIK osmo-bts-trx is also affected by these changes, as at some point its specific code calls l1sap_up to push packets up to the stack into l1sap_tch_ind() for TCH data.
I've just looked again through the patches at https://gerrit.osmocom.org/#/q/topic:rtp-fixes and I can't find any changes in src/osmo-bts-trx/ - only in src/osmo-bts-sysmo/, src/osmo-bts-litecell15/ and src/osmo-bts-octophy/. Do you mean that osmo-bts-trx inherits the related code from one of them (sysmo?)?
Over that region, there should be 2 changes in behaviour:
- In case empty data is received, it will update the RTP Clock accordingly.
I was under impression RTP clock is maintained by the upper levels?
Possible issues on osmo-bts-trx layer I can image:
- As explained by Harald in the original description, early exits: "osmo-bts-trx has all kinds of other "early exit" paths in rx_tchf_fn() and rx_tchh_fn(), but they seem less critical as they only occur in cases of memory allocation failure or completely wrong RSL channel mode (with associated error messages)."
It indeed looks like it exits early only on OOM or wrong channel type, which is probably correct.
- osmo-trx losing to trigger an event.
- UDP packet being lost between osmo-trx and osmo-bts-trx. --> should be possible to check for gaps and create dummy packets then push them up the stack.
IIRC osmo-bts-trx tries to schedule processing of all bursts even if it doesn't receive them from osmo-trx because the latter was originally doing a lot of gating and didn't pass noise bursts up. Have you looked at whether this logic handles what we need for this patch series to work correctly?
Updated by pespin over 6 years ago
ipse wrote:
Thank you for the explanation!
pespin wrote:
AFAIK osmo-bts-trx is also affected by these changes, as at some point its specific code calls l1sap_up to push packets up to the stack into l1sap_tch_ind() for TCH data.
I've just looked again through the patches at https://gerrit.osmocom.org/#/q/topic:rtp-fixes and I can't find any changes in src/osmo-bts-trx/ - only in src/osmo-bts-sysmo/, src/osmo-bts-litecell15/ and src/osmo-bts-octophy/. Do you mean that osmo-bts-trx inherits the related code from one of them (sysmo?)?
No, I mean the low level layer is osmo-bts-trx specific, and when it handles packets up the stack at some point it reaches common code [l1sap_up(), src/common/l1sap.c]. The device-specific code in osmo-bts-trx is quite different than the one of the other devices. The other devices all share a quite similar code structure. That's why I didn't touch that one and at first glance didn't look like suffering from the exact same issue.
Over that region, there should be 2 changes in behaviour:
- In case empty data is received, it will update the RTP Clock accordingly.I was under impression RTP clock is maintained by the upper levels?
"Over that region", I meant "over the upper layers which contain shared code", so yes, RTP clock is maintained by upper levels :-)
IIRC osmo-bts-trx tries to schedule processing of all bursts even if it doesn't receive them from osmo-trx because the latter was originally doing a lot of gating and didn't pass noise bursts up. Have you looked at whether this logic handles what we need for this patch series to work correctly?
Which means as far as I understand that there should be no issue of losing events and you confirm that no work needs to be done on osmo-bts-trx specific code. It's interesting to notice too that if that's not the case (if some events are lost in osmo-bts-trx), you still could be able to reproduce the RTP clock issue without this patchset when DTX is not being used.
Updated by ipse over 6 years ago
pespin wrote:
ipse wrote:
IIRC osmo-bts-trx tries to schedule processing of all bursts even if it doesn't receive them from osmo-trx because the latter was originally doing a lot of gating and didn't pass noise bursts up. Have you looked at whether this logic handles what we need for this patch series to work correctly?
Which means as far as I understand that there should be no issue of losing events and you confirm that no work needs to be done on osmo-bts-trx specific code. It's interesting to notice too that if that's not the case (if some events are lost in osmo-bts-trx), you still could be able to reproduce the RTP clock issue without this patchset when DTX is not being used.
Well, I haven't confirmed this as I have neither looked at nor tested this recently, but this is my recollection of its behavior.

